Non-Human Identity Security Management Framework
Non-human identities (NHIs) now outnumber human accounts by ratios exceeding 100:1 in most enterprises. A single Kubernetes cluster spawns hundreds of pod identities as workloads auto-scale. GitHub Actions generate unique OIDC tokens for each CI/CD run. AI agents create identity chains that are hard for security teams to discover.
Identity and access management (IAM) systems were built around human patterns: employees who log in during business hours and follow HR-driven lifecycle events, such as joining a company and leaving. These systems fail when machine identities exist for only milliseconds or when they autonomously spawn new identities across public cloud, AI agents, and containerized platforms without centralized tracking.
This article addresses these challenges by discussing three pillars:
- Identity Lifecycle Management - discovers and manages identities throughout their lifecycle
- Identity Governance and Administration - establishes policies and controls
- Identity Threat Detection and Response - detects and contains threats at machine speed.
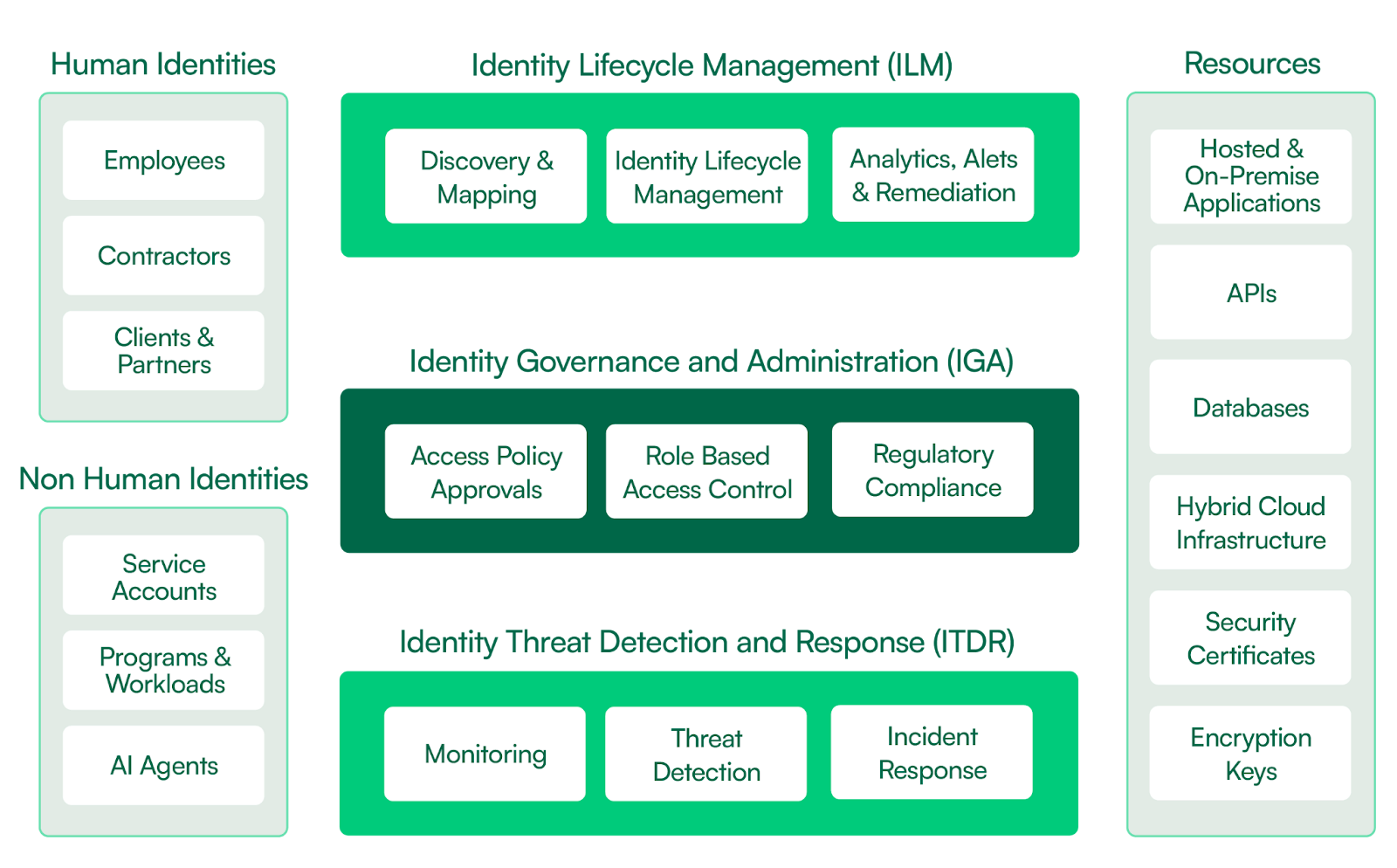
Summary of key non-human identity security concepts
Understanding identities
Before diving into the framework, we need to understand what makes non-human identities fundamentally different from human accounts, and why discovering, managing, and securing them requires a different architecture.
There are four categories of identities.
{{b-list="/inline-cards"}}
Human identities
Human identities include employees, contractors, and partners who authenticate through traditional methods. These are the identities like usernames paired with passwords, multi-factor authentication protecting sensitive access, and centralized directories that map people to permissions.
When someone joins an organization, HR creates a ticket, and when they leave, HR closes that ticket. The lifecycle is predictable because it's tied to employment events that happen on a human timescale.
Service identities
Service identities are static accounts with long-lived credentials that persist across months or years. An API user account that's been running the same batch job for three years is a good example. These identities authenticate using API keys, client secrets, or certificates that don't expire automatically.
Their persistence makes them high-value targets. If one of these credentials is compromised, an attacker could maintain access until the issue is noticed and manually revoked.
Workload identities
Workload identities are dynamic and ephemeral, with a short lifespan. For example, containers request service account tokens when they start, use those tokens to authenticate to APIs, then terminate when the workload completes. Another example is an AWS Lambda function that assumes an IAM role, executes its handler function, and terminates, all within 200 milliseconds.
These identities follow the lifecycle of the compute resources they're attached to, so their creation and destruction occur automatically without human intervention.
Agentic AI identities
Agentic AI identities are also to be considered, but require special attention because they introduce non-determinism into identity management. An autonomous agent receiving a user request might create credentials to access cloud storage or call external APIs.
Still, the exact sequence of identity creation depends on how the agent interprets the request. The same agent processing the same user input might take different paths on different days, creating different identity chains. Traditional approaches that rely on predictable patterns break down when the behavior itself is probabilistic rather than deterministic.
Why NHIs need a different security architecture
Human identity management rests on assumptions that seem obvious until you apply them to machine identities.
Authentication
Humans authenticate by proving who they are, using:
- Something they know (password)
- Something they have (a hardware token), or
- Something they are (biometric).
Multi-factor authentication combines these factors to increase security. However, machine identities can't use MFA in the traditional sense. They authenticate through certificates, API keys, or temporary tokens that must work without human interaction.
For instance, a service account making 10,000 API calls per second is expected behavior. But the same pattern from a human account would trigger immediate lockdown because no person can authenticate that rapidly.
The authentication mechanisms themselves are different because the usage patterns are machine-speed rather than human-speed.
Lifecycle
Lifecycle differences also create complexity at every stage. Human identities have predictable lifecycles of 2 to 5 years. The human identity lifecycle is driven by HR events that happen slowly enough for manual processes to work. On the other hand, machine identities might exist anywhere from three seconds to three years. For example, a Kubernetes pod identity exists for the duration of the pod's lifecycle, and might span less than ten seconds.
You can't rely on annual access reviews when identities are created and destroyed thousands of times per day. Automation is a must as manual oversight is physically impossible at this scale.
Ownership
In human IAM, ownership is straightforward: Jane reports to Joe, so Joe approves Jane’s access requests.
With non-human identity, ownership becomes recursive in ways that break traditional hierarchies. Machine identity ownership follows technical rather than organizational hierarchies. For example, Terraform provisions a Lambda function that assumes an IAM role, which generates temporary S3 credentials via STS.
Tracing this chain back to the original human owner requires analyzing relationships across multiple systems: your infrastructure-as-code repository, AWS CloudTrail logs, and IAM policy documents. The chain might be five or six layers deep before you reach a human name.
Understanding who's responsible when a service credential performs an unexpected action requires traversing the entire graph.
Scale
When managing tens of thousands of systems distributed across cloud providers, container orchestrators, CI/CD pipelines, and SaaS platforms, scaling identity security becomes a challenge. Each system maintains its own identity model, with different terminology, APIs, and logging formats.
For example, AWS calls them IAM roles, Kubernetes calls them service accounts, while Google Cloud has both service accounts and workload identities, and Azure calls them service principals. Correlating these identities across platforms requires understanding the semantic equivalences between different naming conventions while processing millions of authentication events per hour.
Identity lifecycle management (ILM) overview
Identity lifecycle management (ILM) tracks non-human identities from creation to deletion. NHI lifecycles follow five distinct phases triggered by infrastructure events rather than HR processes:
- Provisioning
- Monitoring
- Rotation
- Audits
- Retirement
Each stage requires automation to handle the scale and velocity of machine identities. Three levels of visibility are needed:
- Static analysis examines infrastructure-as-code templates and codebases to find identities defined in configuration.
- Dynamic analysis processes authentication logs to discover active identities.
- Behavioral inference examines API activity patterns to identify identities that never interact with centralized authentication systems.
The challenge is correlating fragments across these three levels to build identity chains that trace back to responsible owners.
{{b-table="/inline-cards"}}
Discovery and mapping in ILM
Discovery starts by going beyond the basic inventory that captures only what identity providers know. The identities that don't appear in your IAM console are often the ones that pose the most significant risk. For example, you need to infer NHIs from CloudTrail events, API logs, and metadata that traditional tools miss.
Challenges
The following table shows where NHIs hide across your infrastructure and what makes each category challenging to discover:
Hence, discovery requires API-based approaches capable of processing millions of events per second. Agent-based solutions fail at this scale because deploying agents to every container, function, and service creates deployment complexity that doesn't scale. Each new service requires agent installation, configuration, and maintenance. When containers are created and destroyed every few seconds, agent deployment slows everything down and consumes resources that could be used to run workloads.
Example
Consider how you'd discover OIDC identities used by GitHub Actions workflows. These tokens exist for minutes, authenticate through AssumeRoleWithWebIdentity, and are never stored as persistent identities in AWS IAM.
Your tooling should be able to analyze CloudTrail events, specifically looking for this pattern:
{
"eventName": "AssumeRoleWithWebIdentity",
"userIdentity": {
"type": "WebIdentityUser",
"userName": "repo:myorg/myrepo:ref:refs/heads/main"
}
}
The userName field contains the repository and branch information encoded in the OIDC token. By parsing these events in real-time, you discover which repositories are assuming which AWS roles without ever seeing the actual token.
jenkins-deploy-sa (namespace: ci-cd)
├─ RoleBinding: jenkins-deployer
│ └─ Role: deploy-permissions
│ ├─ create deployments
│ ├─ update services
│ └─ read configmaps
└─ Owned by: DevOps team
├─ Jane (primary owner)
├─ John (secondary)
└─ Carol (on-call rotation)
This chain shows that the jenkins-deploy-sa service account inherits permissions from a role that grants specific Kubernetes API access.
When the service account does something unexpected, like trying to delete namespaces instead of creating deployments, you know exactly who to contact. More importantly, you understand the scope of what this identity should be doing versus what it's actually attempting.
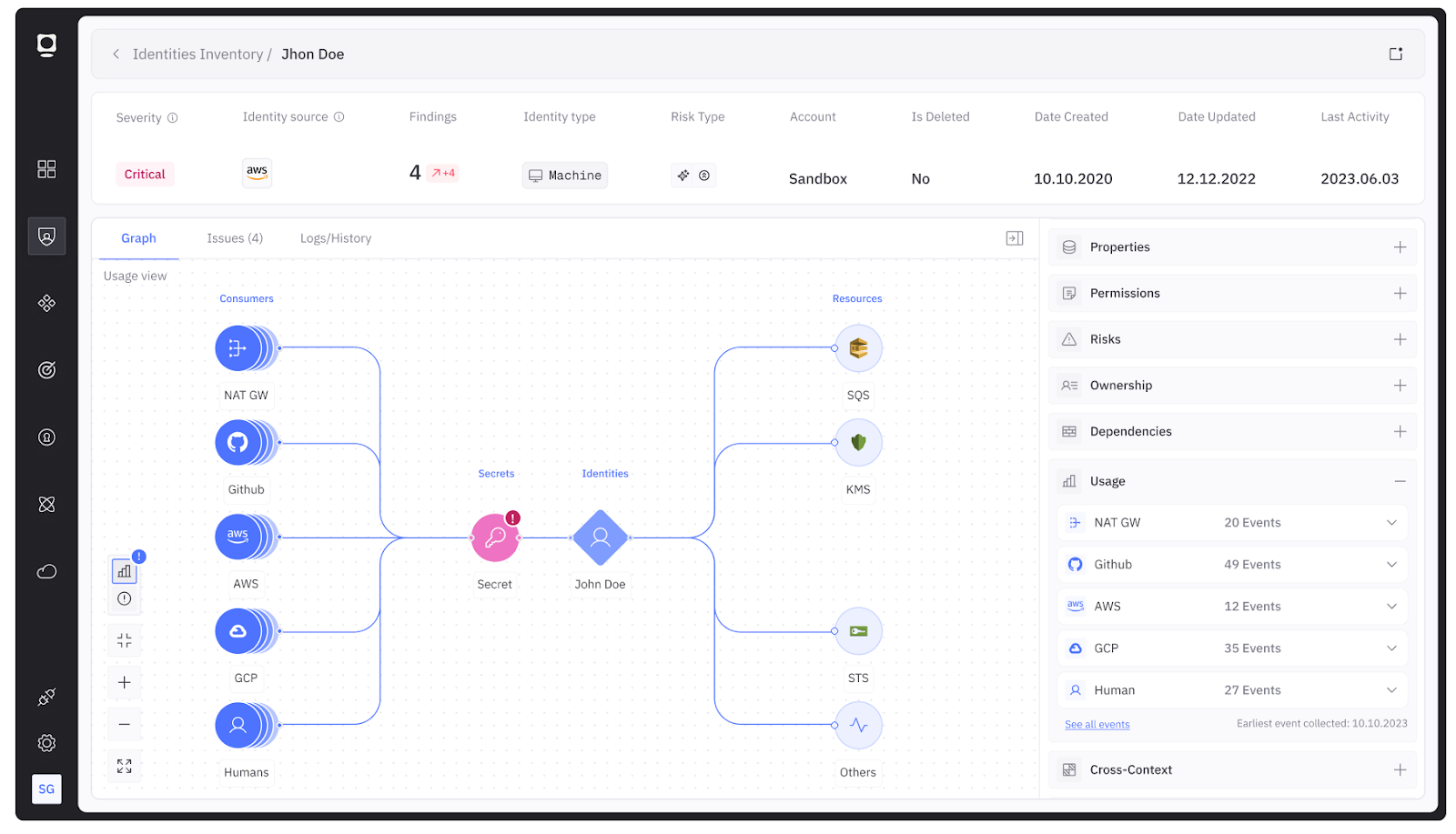
How Token Security helps
Token Security is an agentic AI and non-human identity security solution that solves discovery through a unified identity graph that automatically correlates identities across 100+ integration points without requiring agents. The platform ingests CloudTrail events, Kubernetes audit logs, CI/CD platform webhooks, and SaaS API logs simultaneously, building a real-time map of every identity and its relationships.
ILM lifecycle phases
Non-human identity security must consider the following phases
Provisioning
Provisioning establishes permissions from the moment of creation. Infrastructure-as-code templates enforce least-privilege and time-bound credentials before the identity ever authenticates. You can configure it to set maximum session durations appropriate to the use case, for example, one hour for OIDC tokens used in CI/CD workflows, twelve hours for STS credentials used by long-running batch jobs:
aws iam create-role \
--role-name lambda-s3-processor \
--max-session-duration 3600 \
--assume-role-policy-document file://trust-policy.json
The trust policy includes conditions that add security layers: only Lambda functions running in your specific AWS account can assume this role, preventing cross-account assumption even if someone discovers the role ARN.
Terraform (or similar tools) can automatically scope permissions to specific workloads:
resource "kubernetes_role" "app" {
rule {
resources = ["configmaps"]
verbs = ["get", "list"]
resource_names = ["${var.app_name}-config"] # Scoped to specific ConfigMap
}
}
The resource_names field maintains least privilege at scale by restricting access to specific resources rather than all resources of a given type.
Monitoring
Monitoring tracks the active state throughout the identity's lifetime. Continuous behavioral tracking captures machine-to-machine interactions, building a profile of normal behavior. API-level telemetry establishes pattern-of-life baselines: how often the identity authenticates, which endpoints it calls, and what resources it accesses. Once baselines exist, anomaly detection can flag deviations from established patterns.
Rotation
Credential longevity inversely correlates with security risk, meaning the longer a secret exists, the more likely it is to be leaked to logs or committed to repositories.
Rotation refreshes credentials on a schedule that balances security and operational complexity. You should automate rotation every thirty days for high-privilege identities, ninety days for standard access.
Here is an example of Lambda rotation implementing a four-step workflow:
- Create a new secret
- Set it in the target service
- Test that it works
- Mark as current
aws secretsmanager rotate-secret \
--secret-id prod/database/api-user \
--rotation-lambda-arn arn:aws:lambda:us-east-1:123456789012:function/Rotate \
--rotation-rules AutomaticallyAfterDays=30
Audits
Audits are done continuously rather than quarterly. Permission drift analysis compares the current state against the initial baseline:
# Compare current policy against baseline
aws iam get-role-policy --role-name production-deployer --policy-name DeploymentPolicy > current.json
diff baseline.json current.json
Real-time posture assessment confirms continuous alignment with governance standards, catching misconfigurations within minutes rather than during quarterly reviews.
Retirement
Retirement decommissions cleanly when workloads terminate. Automated cleanup triggers through infrastructure lifecycle hooks. Lambda functions can revoke unused access keys based on last-used timestamps, preventing orphaned identities from lingering with valid permissions.
Token Security enables you to automate the NHI lifecycle through playbooks, preventing drift, eliminating unused identities, and enforcing least privilege at scale. It automates key rotation, stale account removal, and ties identities to IaC for full auditability and response.
Analytics, alerts, and remediation in ILM
Analytics, alerts, and remediation complete the ILM pillar by turning visibility into action. Once you’ve discovered identities and established lifecycle controls, you need continuous monitoring to detect anomalies and automated remediation to respond at machine speed.
Building pattern-of-life baselines for each NHI type is the foundation for alerting. A build pipeline identity that typically runs from 8 am to 6 pm on weekdays, but suddenly executes at 2 am on Sunday, should prompt an investigation. A database backup service account that accesses exactly three S3 buckets nightly for two months, then suddenly starts accessing a fourth bucket, should raise a flag. These deviations from established patterns often indicate credential compromise or unauthorized usage.
Contextual risk scoring
Contextual risk scoring weighs multiple factors: permission scope (0-10), exposure (0-10), anomaly score (0-10), and time since rotation (days):
R = (P × E × A) / T
An identity with admin permissions (P=10), internet exposure (E=8), highly anomalous behavior (A=9), and 180-day-old credentials scores 4.0. Scores above 3.0 trigger automated remediation. Scores 1.0-3.0 generate alerts for human review. Below 1.0 are logged without active alerting.
AI-powered analysis
Token Security utilizes AI-powered analysis to assess permission scope, age, and activity patterns, achieving over 90% accuracy in ownership detection. Behavioral baselines require a 14-day training window to achieve 95% accuracy. The system builds probability distributions for each NHI covering time-of-day usage, API call frequency, and resource access patterns.
Anomaly detection compares current behavior against baselines using multiple signals, including:
- Volume deviation (10,000 API calls vs. the usual 100/hour)
- New endpoints accessed
- Timing anomalies (activity during historically quiet hours), and
- Changes in resource access.
Remediation must understand downstream dependencies to avoid breaking production systems. Token Security provides exact commands customized for your environment:
# Context-aware remediation workflow
kubectl get pods -n production --field-selector spec.serviceAccountName=risky-sa
kubectl create serviceaccount payment-processor-sa -n production
kubectl patch deployment payment-processor -p '{"spec":{"template":{"spec":{"serviceAccountName":"payment-processor-sa"}}}}'
kubectl delete serviceaccount risky-sa -n production
This approach prevents service disruption by creating the replacement identity, migrating workloads, verifying health, and only then removing the compromised credential.
{{b-watch="/inline-cards"}}
Identity governance and administration (IGA)
Governance controls what machine identities can access and under what conditions. While lifecycle management handles creation through retirement, governance defines the rules that identities must follow throughout their existence.
Access policy approvals
Three approval paths accommodate the different risk levels, all designed not to get in the way of development efforts.
The standard path flows through IaC pull requests, treating identity changes as code changes. For example, you can have automated validation to check syntax and policy compliance:
# Automated policy validation
- name: Validate against policy
run: |
# Check for overly permissive policies
if grep -r "Effect.*Allow.*Action.*\*" terraform/iam/; then
echo "ERROR: Found wildcard permissions"
exit 1
fi
Peer review happens after automated checks pass to verify that the requested permissions align with business needs.
The privileged path requires explicit approvals for elevated access, such as when a developer needs temporary admin access to debug a production issue. They submit a request that describes the elevated access required, provides business justification, and specifies the expected duration. The system then grants time-bound access and automatically revokes it when the access is complete.
The emergency path provides break-glass access for incidents where approval workflows would delay critical response. Temporary elevation should last a maximum of four hours with automatic revocation:
aws iam attach-role-policy --role-name incident-response-role \
--policy-arn arn:aws:iam::aws:policy/SecurityAudit
# Scheduled auto-revocation after 4 hours
Mandatory post-incident review and prevention documents explain why emergency access is needed.
The audit trail should be maintained across the approval process through integration. For example, ServiceNow can track approval workflows with ticket numbers that tie back to specific identities, while Jira documents access requests and their business justification, creating a searchable history. Platforms like Token Security simplify this by unifying approval routing across multiple systems, correlating approval events from different tools into a single timeline.

Role-based access control
Hierarchical permission models contain blast radius at each boundary. The organization boundary sits at the top, enforced through Service Control Policies in AWS Organizations or tenant policies in Azure. Below that, the environment boundary separates production, staging, and development through account-level policies.
The service boundary uses IAM policies to isolate payment services from user services from authentication services. Finally, the function boundary applies role-based controls to distinguish read-only access from write and administrative access.
Each NHI inherits constraints from the level above. A development service account can't access production resources even if someone accidentally grants those permissions; the environment boundary blocks it through Service Control Policies (in AWS):
{
"Effect": "Deny",
"Action": "*",
"Resource": "*",
"Condition": {
"StringEquals": {"aws:RequestedRegion": "us-east-1"},
"StringLike": {"aws:PrincipalArn": "arn:aws:iam::111111111111:*"}
}
}
This SCP denies all actions for principals from the development account in the production region, preventing cross-environment access at the organization level.
Context-aware restrictions also add dynamic controls based on time, location, or state.
// Temporal: Backup account only active 2-4 am
{"Condition": {"DateGreaterThan": {"aws:CurrentTime": "2024-01-01T02:00:00Z"}}}
// Network: Restricted to corporate IP ranges
{"Condition": {"IpAddress": {"aws:SourceIp": "10.0.0.0/8"}}}
Regulatory compliance
Immutable audit logs capture every identity-related event across your infrastructure.
If you’re using AWS, these logs aggregate platform access from all AWS accounts into a single searchable index, making it straightforward to trace credential lifecycles from creation through rotation to revocation, along with the approval chains behind every permission change.
This centralized visibility means you can quickly identify potential issues. For example, a simple query revealing thousands of describe calls from a single assumed role often indicates reconnaissance activity or a misconfigured monitoring setup that needs attention.
Compliance should be automated, rather than manually compiling evidence during audit season. Compliance scorecards map controls to frameworks in real-time and generate the reports auditors need. For instance:
- SOC2 quarterly reviews can include direct evidence links to source data.
- PCI DSS tracking monitors rotation schedules and warns teams 75 days before they breach the 90-day requirement.
- ISO 27001 documentation captures each identity's complete lifecycle from initial justification through approval workflows to eventual retirement.
A continuous approach transforms compliance from a periodic scramble into an always-on discipline. Real-time dashboards surface current posture immediately, so drops in rotation compliance or least-privilege adherence become visible when they happen rather than months later during annual audits.
Identity threat detection and response (ITDR)
The gap between compromise and threat containment must be measured in seconds rather than hours. Otherwise, attackers gain access to resources, exfiltrate data, and establish persistence before you can react.
Monitoring
Three-tier telemetry collection feeds the detection engine, with each tier providing different types of insights that combine to create visibility:
Data flows through a normalization layer that converts vendor-specific formats into a unified schema, enabling correlation across platforms and tracking how a compromised GitHub PAT led to AWS access, which in turn enabled lateral movement into Azure.
Detecting anomalies in machine-speed operations requires understanding normal behavior at a granular level. Why did a deployment service account that only ever calls DescribeInstances suddenly call GetSecretValue? That endpoint access pattern change should be investigated, even if the individual calls are authorized.
Similarly, a GitHub Action downloading the entire codebase instead of specific directories suggests credential theft.
Token Security ingests CloudTrail, Azure Activity Logs, and Kubernetes audit logs simultaneously, processing them in real-time streams rather than batch jobs. Because it integrates with your stack, the platform captures ephemeral identities that exist for seconds and correlates their activity with the rest of the system.
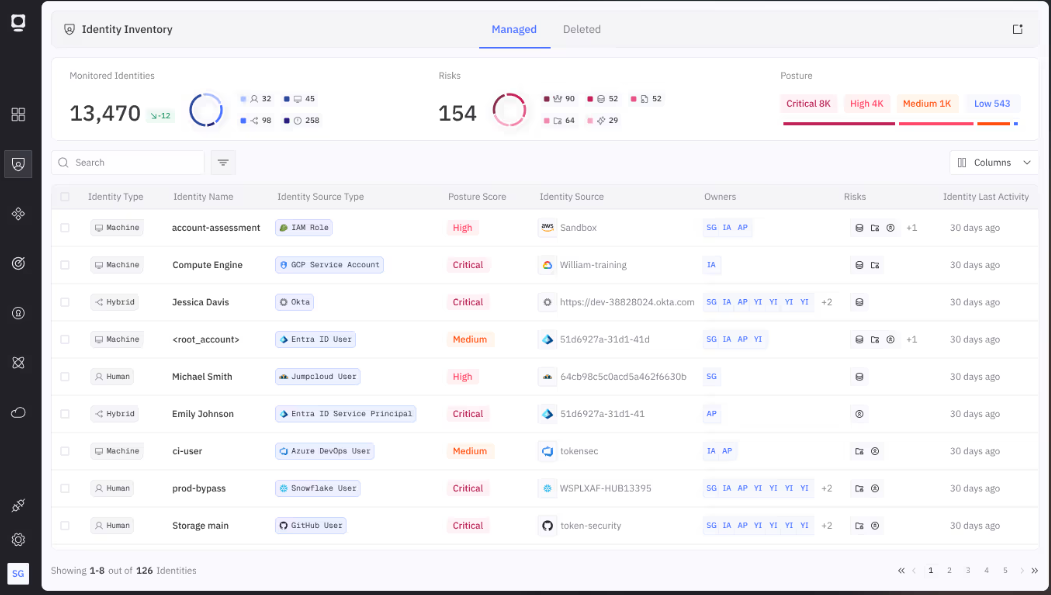
Threat detection
NHIs face credential theft (repository leaks, CI/CD compromise), permission escalation (self-modification, unauthorized role assumption), and lateral movement through identity chains. Attacks complete in seconds and require two parallel detection approaches:
Deterministic rules
Deterministic rules match known negative patterns with zero false positives. These example rules trigger immediate alerts because they represent patterns that shouldn't occur in legitimate operations:
- When a service account authenticates from an unexpected geographic region, for instance ap-southeast-2, when your infrastructure only runs in us-east-1 and eu-west-1
- Identity self-modification attempts, in which an identity seeks to elevate its own permissions, are always malicious.
- Simultaneous access key usage from multiple IP addresses indicates credential sharing or theft, since a single key can't legitimately authenticate from geographically distinct locations within seconds.
- Cross-account role assumption from unapproved external accounts points to either misconfigured trust relationships or active exploitation.
Probabilistic models
Probabilistic models calculate the statistical likelihood that behavior is malicious rather than legitimate. Instead of matching exact patterns, they detect deviation from baseline behavior.
When an identity that usually makes 100 API calls per hour suddenly makes 10,000, the model calculates the likelihood that this surge is legitimate rather than a compromise. The scoring incorporates multiple signals: volume deviation, new endpoints accessed, timing anomalies, and resource access changes, with scores above 7.0 triggering automated investigation workflows.
Detection fidelity improves continuously through feedback loops that tune both models. False positives cause the system to reduce detection thresholds, so if legitimate weekend deployments trigger alerts, the temporal model adjusts its expectations. Conversely, missed incidents generate new deterministic rules, transforming attack techniques that slipped through into explicit patterns for future detection.
Incident response in ITDR
Automated containment for compromised NHIs must be immediate. For IAM roles, this means attaching explicit deny policies that override all other permissions. For access keys, immediate deletion prevents further use. Kubernetes service accounts require deleting token secrets and forcing pod recreation to issue new tokens.
aws iam put-role-policy --role-name compromised-role \
--policy-name EmergencyDenyAll \
--policy-document '{"Effect":"Deny","Action":"*","Resource":"*"}'
The containment workflow goes beyond just the compromised identity by understanding relationships across your infrastructure. The system:
- Preserves the current state for forensic analysis before making any changes.
- Identifies the blast radius by analyzing the identity graph to identify downstream identities and accessible resources.
- Revokes not only the primary identity but also any downstream identities created after the compromise timestamp.
This ensures that the attacker's foothold is completely removed.
Affected parties receive automated alerts with contextually relevant remediation playbooks, while the system updates threat intelligence to improve future detection of similar attack patterns. Tracing attack paths through identity chains reveals the full scope of what happened.
Example
Consider how an attacker might move laterally through your infrastructure:
Initial Compromise
└─ Developer GitHub Account (jane@company.com)
└─ GitHub Personal Access Token (compromised via phishing)
└─ GitHub Actions Workflow (triggered with malicious commit)
└─ AWS OIDC Role (github-actions-deployment-role)
├─ Temporary STS Credentials (1 hour validity)
│ ├─ ECR: Pushed malicious container image
│ ├─ S3: Listed all buckets in account
│ └─ Lambda: Modified function code
└─ Assumed Additional Role (lambda-admin-role)
└─ RDS: Attempted database access (blocked by network policy)
This graph shows how a compromised developer account is the entry point for a chain of escalating access. The attacker used a stolen PAT to trigger a GitHub Actions workflow, which assumed an AWS role through OIDC federation and obtained temporary credentials. Some actions succeeded, such as pushing malicious container images to ECR, listing S3 buckets, and modifying Lambda functions, while others were blocked by network security groups that prevented RDS access.
Understanding this complete chain helps you determine what data may have been exposed and which systems need additional investigation.
Recovery maintains service availability through blue-green rotation rather than immediate revocation. The approach creates replacement identities with fresh credentials, gradually migrates workloads to use them, verifies health, and only then removes the compromised credentials:
# Blue-green credential rotation
kubectl create serviceaccount production-api-sa-v2 -n production
kubectl patch deployment production-api \
-p '{"spec":{"template":{"spec":{"serviceAccountName":"production-api-sa-v2"}}}}'
kubectl rollout status deployment/production-api --timeout=120s
kubectl delete serviceaccount production-api-sa -n production
In this sequence, new identities are established before old ones are removed, thereby preventing service disruption during the response process.
The entire response follows the OODA loop adapted for machine speed:
- Observe the alert
- Orient through identity graph analysis
- Decide via automated triage
- Act to contain the threat.
Critical incidents complete this cycle in under 60 seconds. Recovery applies immutable infrastructure principles, destroying and rebuilding compromised identities from infrastructure-as-code rather than attempting to clean them:
resource "aws_iam_role" "application_role" {
name = "application-role"
lifecycle {
create_before_destroy = true
}
}
This guarantees that no attacker-placed backdoors survive the remediation process. The benchmark for mean time to resolution is a short time from initial detection to complete remediation for critical incidents.
Adapting the framework for AI agents
AI agents introduce unique challenges that require adapting each pillar of the framework. The non-deterministic nature of agent behavior means that traditional security controls, designed around predictable patterns, need to evolve.
Discovery is non-deterministic because you can't predict what identities will exist. The same agent receiving the same user request might create different identity chains depending on the conversation history or available tools. Effective discovery requires capturing identities in real-time, tracking the full context: which user prompted the action, what the agent was trying to accomplish, and which resources it needed.
Advanced platforms enable security teams to query this context through natural language integrated with tools like Claude, ChatGPT, or Cursor:
- "Which AI agents have created identities in the last 24 hours?"
- "Show me the identity chains created by our customer support agent."
- "What resources are our AI agents accessing most frequently?"
Agents access resources through NHIs governed by policies that control permitted actions, such as reading from S3 buckets or invoking Lambda functions. Governance requires maximum permission boundaries rather than precise scoping because it is not possible to know in advance what tasks agents will need to perform. Therefore, the solution combines boundaries that define maximum scope with strict time limits. These boundaries allow data access but prevent IAM changes, resource deletion, or security policy modifications.
Detection must evolve from pattern matching to intent analysis. Traditional anomaly detection fails when expected behavior isn't predictable. Instead, platforms analyze the intent behind actions by correlating agent behavior with user prompts. By doing this, you ask:
"Given what the user requested, does it make sense that the agent accessed these resources?" An agent analyzing cloud costs should access billing APIs and cost explorer data. If it suddenly starts modifying Lambda functions or accessing unrelated databases, something is wrong.
The integration of AI-powered analysis creates a feedback loop where security platforms use AI to understand and secure AI-generated identities. Token Security does this through an MCP server that integrates with existing AI tools and a native AI agent within the platform, providing the contextual awareness needed to manage non-deterministic behavior at scale.
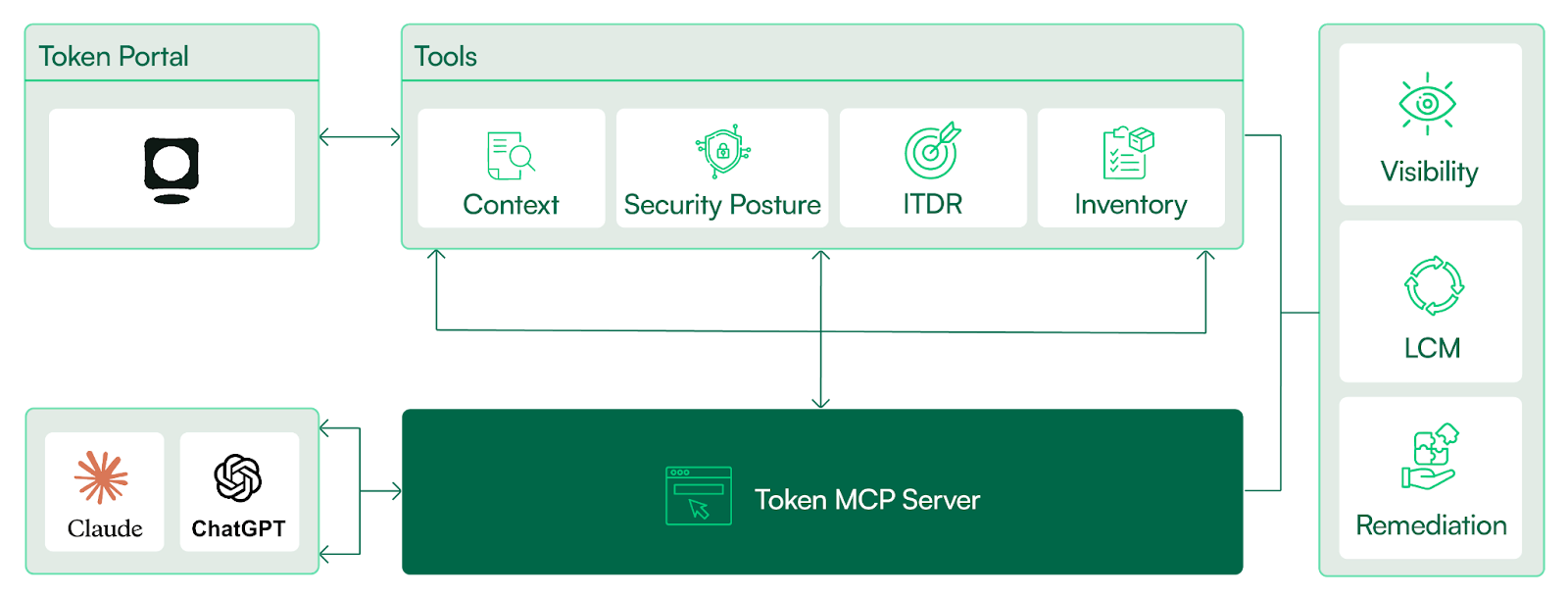
{{b-img="/inline-cards"}}
Conclusion
Non-human identity security requires purpose-built frameworks rather than retrofitting human-focused IAM. ILM, IGA, and ITDR provide structured coverage from discovery through threat response.
Discovery identifies what exists, lifecycle management automates provisioning from creation to retirement, and governance establishes permission boundaries.
Detection and response operate at machine speed through deterministic rules and probabilistic baseline analysis. Proper implementation reduces friction.
Developers spend less time fighting security when service accounts are provisioned automatically. Security engineers focus on strategic work when they have complete visibility and an automated response.
Platforms like Token Security operationalize this framework by processing millions of events per second and correlating activity across cloud providers, containers, and CI/CD systems.
The ratio of machine identities to human accounts is expected to continue increasing. The frameworks you implement today determine whether that growth becomes a vulnerability or a competitive advantage.

